If remarketing is a practice that allows you to display ads to people who have already visited your website, dynamic remarketing goes a step further. It enables you to use automatic ads (containing images, prices, and links) of the very same products the user has previously browsed on your site.
With messages tailored to your audience, dynamic remarketing helps you increase sales by pushing visitors to your site to complete the purchase path. Reminding them how phenomenal your products are.
#1 Leverage discounted products with dynamic remarketing
One of the best remarketing practices is to segment users based on their position in the purchase funnel. That way you can create customized campaigns and ad-groups to adopt different strategies, bids, and budgets.
The most classic subdivision is:
- Users who visit the homepage
- Users who visit the product page
- Users who add a product to the cart
- Users who purchase a product
Challenge
For a dynamic remarketing campaign aimed at users who visit the product page without adding it to the cart, we found that the conversion rate was lower than the objective. So, we decided to change our strategy.
Solution
Leverage discounted products to stimulate sales.
We asked ourselves: what if we try to increase conversions by testing a campaign aimed only at users who have visited a product discounted today? To implement the strategy, we developed a rule in DataFeedWatch to create an ads_label, called “sale”, to associate with all the discounted products. Using the “add static value” feature, we applied the following logic:
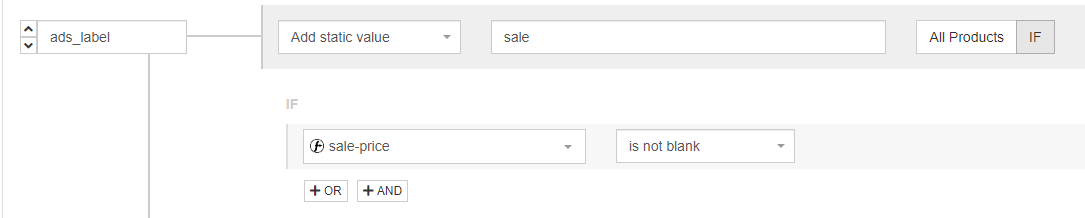
Note:
This is not the classic custom_label attribute, but a specific attribute intended exclusively for display campaigns.
Why use ads_label?
So far, it is one of the very few attributes you can use to filter products in your dynamic ads at the campaign level.
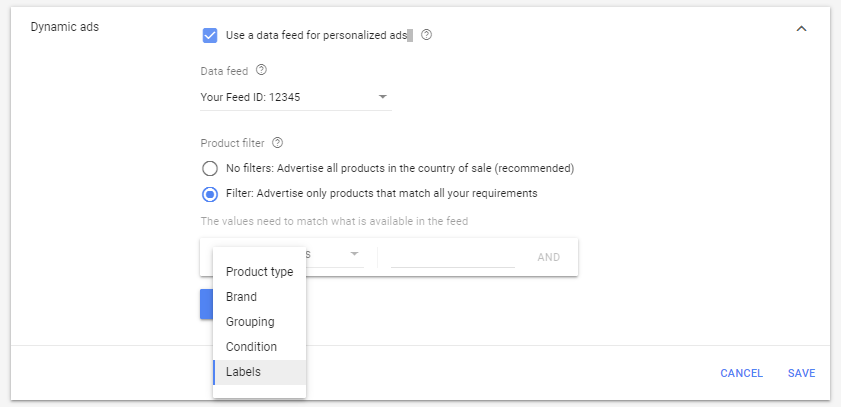
Subsequently, we created a test remarketing campaign - a clone of the original one - which exclusively displayed ads of the filtered products. Namely, the discounted items, to users who in the previous 30 days showed interest in them.
Who among us does not like to take advantage of a discount?

Results
The impact of this strategy has been impressive, both in terms of sales and engagement. The tactic allows the advertiser to take advantage of a natural buying phenomenon, in which users enticed with a discounted offer also discover and purchase other products.
In the test campaign, we recorded an 18% increase in the conversion rate compared to the original one, a 30-second improvement in the average time on the site, with a bounce rate improved by 20%.
The ads’ CTR also increased by 20%, given to the presence of the “Price reduction” layout tag, a feature automatically activated for recently discounted products.
It was filtering the campaign for a subgroup of products that eventually allowed us to take its impression share from 10% to 38%.
Return to top of page or Book an expert feed consultation [FREE]
#2 Prevent failures by using regular expressions
Regular expressions (or regex) are functions or formulas capable of searching, filtering, or replacing text strings following a predefined pattern.
They are widely used in programming and data analysis. And even for us marketers, they represent a Swiss knife to always carry around. For example, when we have used Google Analytics to create view filters, targets, or segments.
Creating complex dependencies between feed attributes can be a powerful tool in digital marketers’ hands. But, it can also become a double-edged weapon if you do not pay attention and take precautions. For those working in the fashion industry, color, size, and materials are fundamental attributes. Both as stand-alone fields and as information to be included in the Title to convert high-quality traffic. In this regard, we recommend this excellent Google guide on the best practices for those working in the fashion sector.
For all our customers in the fashion sector, we usually create the Title dynamically, using different pre-existing attributes in the feed (materials, color, size, product name) and following a rule like:
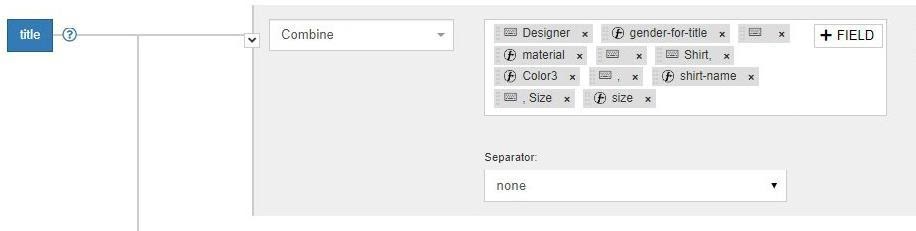
The final result is: Designer Women Cotton Shirt, Red, ProductName, XL.
And so far, everything all right. Often, the Master Fields used in the Title are not provided in the raw data - they have to be extrapolated or created from scratch using the data provided in the source feed. In this specific example, we retrieved the information from a feed column containing information about the colors and materials of the sold items. Product attributes that simply wouldn’t be readable by Google if provided within the original feed column.
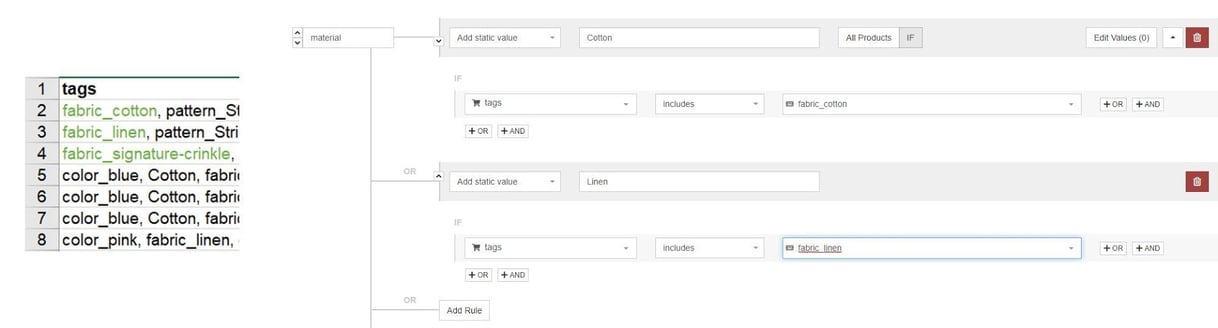
The left part of the image above shows the “tags” column of the source feed. The right part shows an example of how we used that information to develop a rule that creates the “materials” attribute.
Challenge
The limitation of using the “add static value” feature is that only a finite number of variants existing at the moment of creating the rule can be accounted for. In such case, the dynamism is lost. What happens if the customer adds new products to the catalog, with materials not yet categorized or colors and patterns not foreseen until then?
I will tell you...the attributes (e.g. materials, colors, etc.) will be empty, or even worse, they will display incorrect values. As a result, the dependant attributes such as the Title, and eventually, others using those Master Fields (e.g. custom labels, descriptions) will pay the consequences, transforming in something like this:
Designer Women Shirt , , , ProductName, XL
Certainly, it is not an optimized title. I will let you imagine the impact that a situation like this can have. Not only on the performance but also on the structure of your shopping campaigns which, all of a sudden, can stop working.
.png?width=896&name=unnamed(8).png)
Solution
Fortunately for us, back in 1950, a gentleman called Stephen Cole Kleene, American mathematician, together with other confident young men, gave life to what we commonly know as regular expressions.
Using regular expressions, it was possible to create a dynamic and scalable rule - much better compared to the previous solution. This mechanism automatically extracts the present and future information on materials from the source feed, eliminating the risk of compromising the functioning of the dependant attributes.
Here is how to get the same result as in the previous screenshot but in a scalable way, using only simple regex.
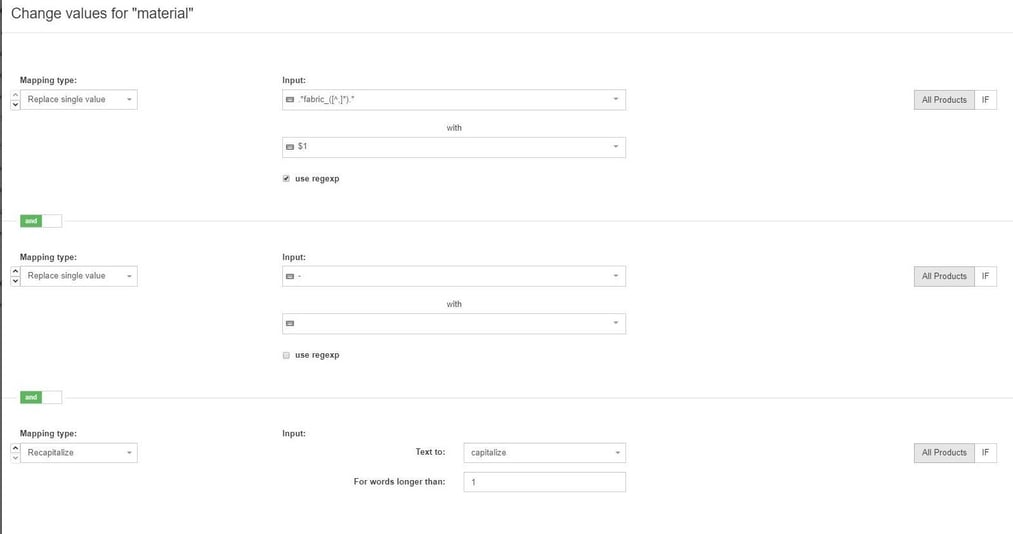
Always remember to test the functioning of regular expressions. The preview option and support offered by DataFeedWatch are of great help with this.
Results
Following this optimization, we were able to prevent feed errors and traffic crashes. Additionally, it allowed us to automate and speed up the categorization of new attributes, color, category, and other product information created by the customer, avoiding tedious manual work on the feed or interventions from the IT department.
These are just two examples of how a data feed management tool together with the power of the human brain, can assist you in testing unconventional ideas and in the prevention and resolution of everyday problems. Helping you to remain competitive and avoid apocalyptic scenarios.
The only limit is creativity, never stop testing!!
--
Enjoyed this article? Check out Michele's Pro Tip on Leveraging Search Partners Network.
Case Study by Midsummer Agency